Multi-turn Agentic Reasoning
AlphaApollo enables multi-turn agentic reasoning by orchestrating foundation models with professional tools to overcome the limitations of model-intrinsic capacity. This approach allows models to engage in deliberate, verifiable reasoning through iterative tool-augmented interactions.
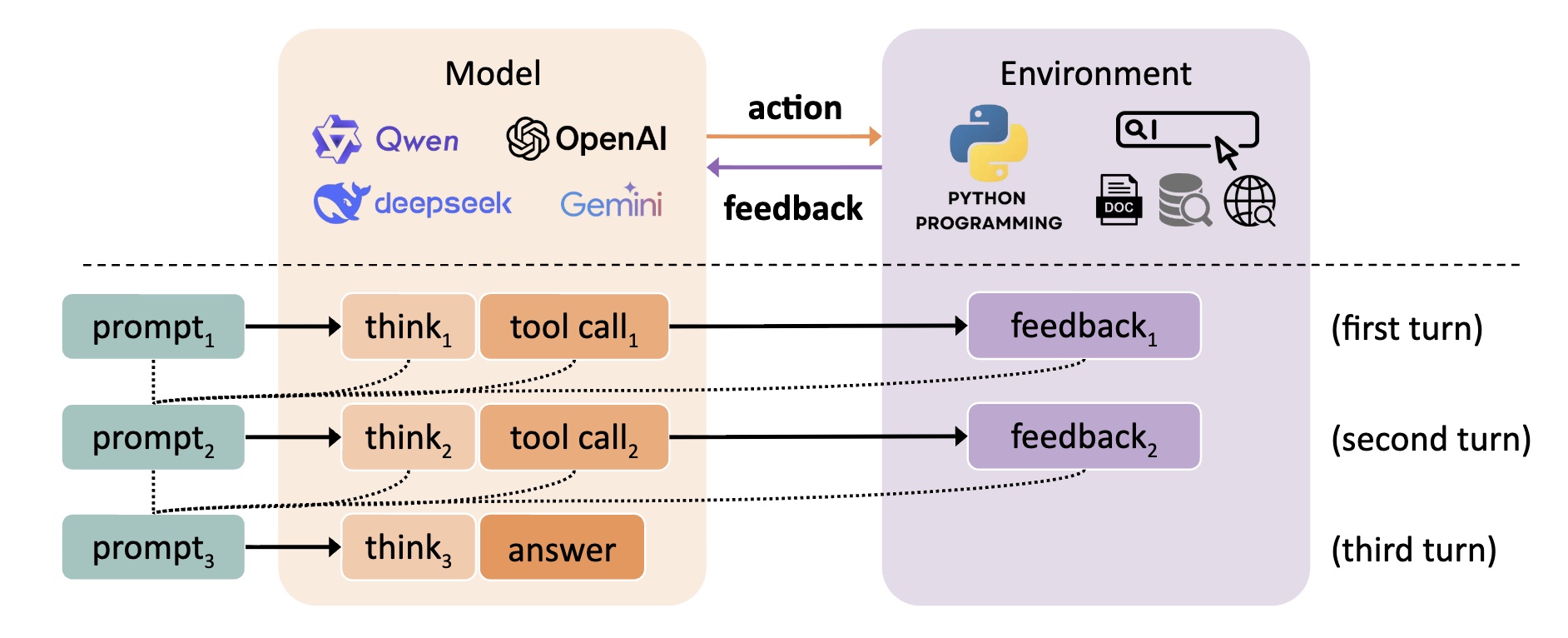
AlphaApollo's reasoning process is an iterative model-environment interaction. The model outputs an action, and the environment provides feedback. Each turn's trajectory is used as the prompt for the next turn, enabling dynamic memory.
Core Components
1. Computation Tool
AlphaApollo integrates a Python interpreter with domain-specific libraries (e.g., SciPy, SymPy) for numerical and symbolic calculations. This enables models to:
- Perform exact mathematical computations beyond token prediction limits
- Execute symbolic manipulations for complex algebraic problems
- Verify solutions through executable code checks
- Generate verifiable, fine-grained feedback for solution refinement
2. Retrieval Tool
The retrieval tool surfaces task-relevant information from external sources, including:
- Library documentation (e.g., SciPy function usage)
- Contextual information needed for problem-solving
How It Works
In a multi-turn reasoning session, the model:
- Analyzes the problem and identifies required computations or information
- Calls appropriate tools (computation or retrieval) to gather necessary data
- Integrates tool outputs into its reasoning process
- Refines the solution based on verifiable results
- Iterates until a satisfactory solution is reached