Multi-round Agentic Evolution
Multi-round Agentic Evolution is AlphaApollo's core mechanism for enabling multiple models to collaboratively evolve solutions through parallel reasoning and shared state management. This approach addresses the challenge of test-time iteration by providing trustworthy feedback and enabling systematic solution refinement.
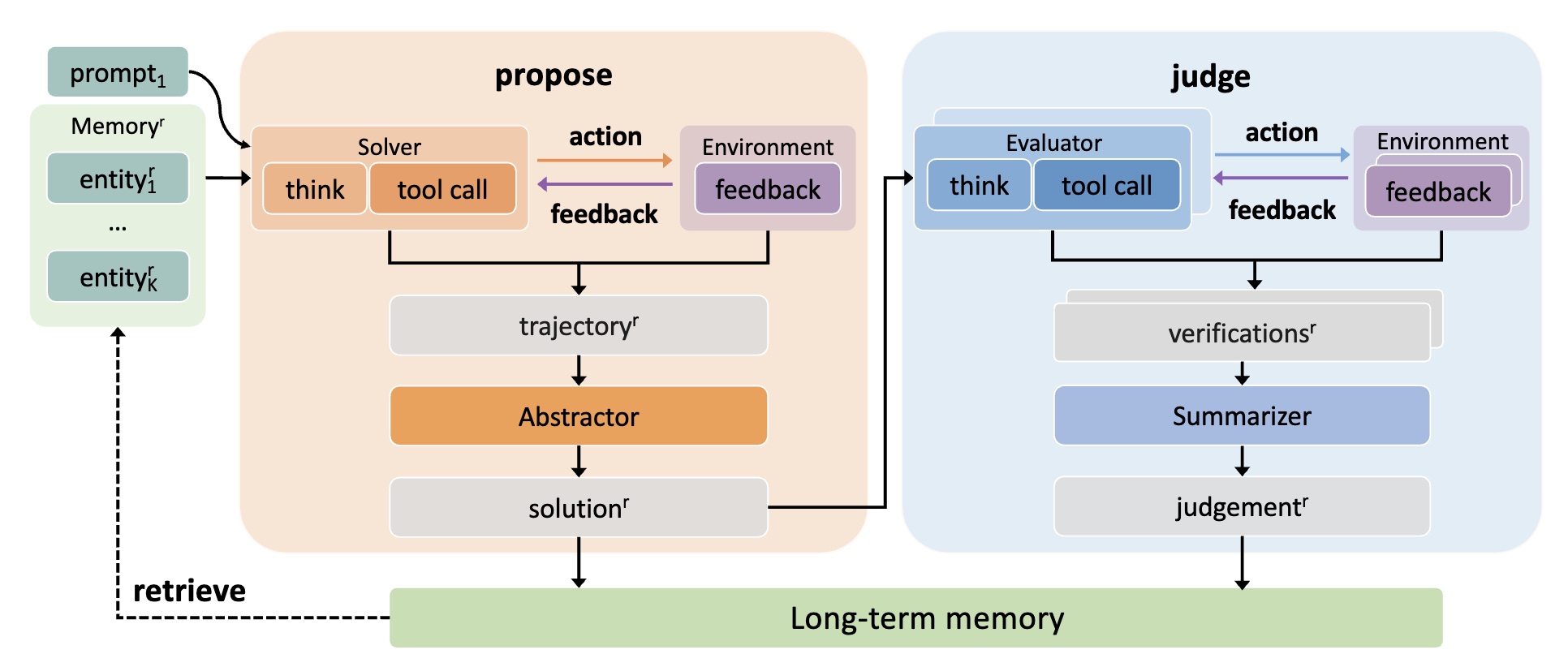
Illustration of multi-round agentic evolution in AlphaApollo. The model iteratively refines its strategies through a propose-judge-update evolutionary loop. A long-term memory is introduced to prevent future errors and promote efficient strategies in subsequent rounds.
Long-term Memory
At the heart of multi-round evolution is a long-term memory that records:
- Candidate solutions: All proposed solutions from different models
- Feedback signals: Fine-grained evaluation outcomes
- Evolution history: How solutions have been refined over rounds
How Multi-Round Evolution Works
1. Parallel Candidate Generation
Multiple models operate in parallel, each with full access to the toolset:
- Each model proposes candidate solutions independently
- Models can use computation and retrieval tools as needed
- All candidates are recorded in the shared memory
2. Tool-Based Evaluation
Each candidate solution undergoes verification:
- Code solutions are executed to produce verifiable results
- Mathematical derivations are checked for correctness
- Logical consistency is validated
- Evaluation results are stored in the memory
3. Refinement
Models reference the shared memory to generate improved solutions:
- Review successful patterns from previous rounds
- Learn from failed attempts and their feedback
- Combine insights from multiple candidate solutions
- Generate refined solutions that build upon prior candidates