Multi-turn Agentic Learning
Multi-turn Agentic Learning enables models to learn and improve through iterative interactions with tools and feedback mechanisms. Unlike static prompting, this approach allows models to adapt their strategies based on verifiable outcomes from tool executions.
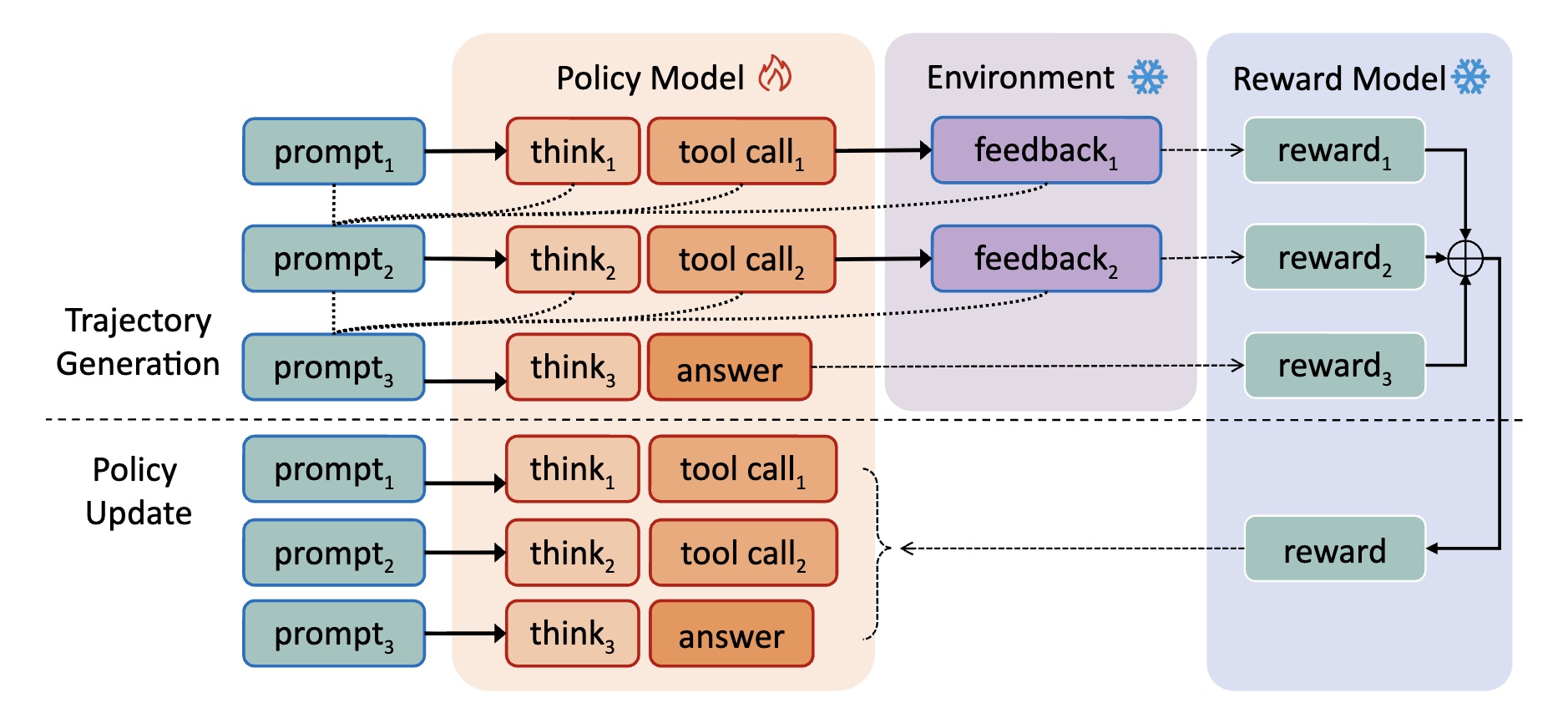
Illustration of multi-turn agentic RL in AlphaApollo. During generation, per-turn rewards are assigned based on model outputs and environment feedback, and summed to form the trajectory reward. During policy update, the policy is updated at each turn with non-model outputs masked.
Learning Through Tool Interaction
In AlphaApollo, models learn by:
- Observing tool outputs: Understanding what works and what doesn't through executable feedback
- Refining strategies: Adjusting problem-solving strategies based on successful patterns
- Building expertise: Accumulating knowledge about effective tool usage and problem decomposition
- Error correction: Learning from failed attempts and tool execution errors
Feedback Mechanisms
1. Execution Feedback
When code is executed, models receive:
- Success/failure indicators
- Output values and intermediate results
- Error messages and stack traces
2. Retrieval Feedback
When retrieving information, models learn:
- Which information sources are most relevant
- How to formulate effective queries
- How to integrate retrieved knowledge into reasoning
Key Benefits
- Multi-tool usage: Models learn how to use multiple tools effectively for different tasks.
- Tool integration in reasoning: Models learn to integrate tools seamlessly into their step-by-step reasoning processes.
- Self-improvement via tool feedback: Models learn to improve their performance by analyzing and learning from the execution feedback.
Previous: Multi-turn Agentic Reasoning |Next: Multi-round Agentic Evolution